
Polyp segmentation에서 SOTA를 기록했던 모델입니다.
pyramid Transformer Encoder와 Local Emphasis라는 강조 모듈을 사용한 Progressive Locality Decoder를 사용해 성능을 높였다고 합니다. 여기서 속도를 개선해 real-time task에 알맞게 만든 모델이 ESFPNet입니다.

Abstract
- 대장내시경은 대장암을 조기에 찾아내는 데에 필요한 폴립 탐지에 가장 효율적인 기술
- 사이즈, 형태가 다 다르고 정상 점막과의 경계도 희미해서 정확한 segmentation이 여전히 도전과제임
- 폴립 이미지가 매우 다양해서 딥러닝 모델조차 현재 데이터셋에 오버 피팅되기 쉬움
- pyramid Transformer encoder를 이용한 SSFormer를 제안
- local feature를 강조하고, attention의 분산을 제한하는 Progressive Locality decoder를 제안
- 학습과 일반화에서 SOTA를 달성
1. Introduction
- 대장암(Colorectal cancer, CRC)은 대장 폴립이 조기에 발견되어 제거될 시에 위험이 줄어듦
- 형태가 다양하고 경계가 모호해서 폴립 segmentation은 여전히 도전과제
- 딥러닝 기반의 polyp segmentation이 비약적으로 정확성을 높임
- CNN 기반의 여러 모델들이 좋은 성과를 보였으나, top-down 모델링 기법과 형태의 다양함에 비해 구조는 단순한 폴립의 특성 때문에 일반화 성능이 부족함
- 일반화 성능을 높이기 위해 Transformer architecture를 포함시킴
- Transformer 모델은 본래 NLP 분야에서 bottom-up 방식의 아키텍처임. 기존의 Transformer는 깊이가 깊어질수록 global feature가 계속해서 혼합, 수렴되어서 attention dispersion을 야기함
- 따라서 multi-scale feature processing에 강한 pyramid Transformer Encoder와 multi-stage feature aggregation 구조인 **Progressive Locality Decoder (PLD)**를 사용함.
- multi-stage feature aggregation은 서로 다른 depth가 서로에게 영향을 줄 수 있으며, 이는 attention dispersion과 local feature의 과소평가를 해결할 수 있음
- Segformer (XIE, Enze, et al.)는 PVT (Pyramid Vision Transformer)의 인코더를 최적화했고, multi-stage feature aggregation decoder를 이용해 다양한 scale과 depth의 피쳐를 upsampling 및 parallel fusion 하여 예측함
- SETR (ZHENG, Sixiao, et al)는 전통적 Transformer를 인코더로, MLA 모델을 decoder로 함
- 이 연구들은 multi-stage feature aggregation이 dense prediction task에서 성능을 비약적으로 높인다는 것을 보여줌

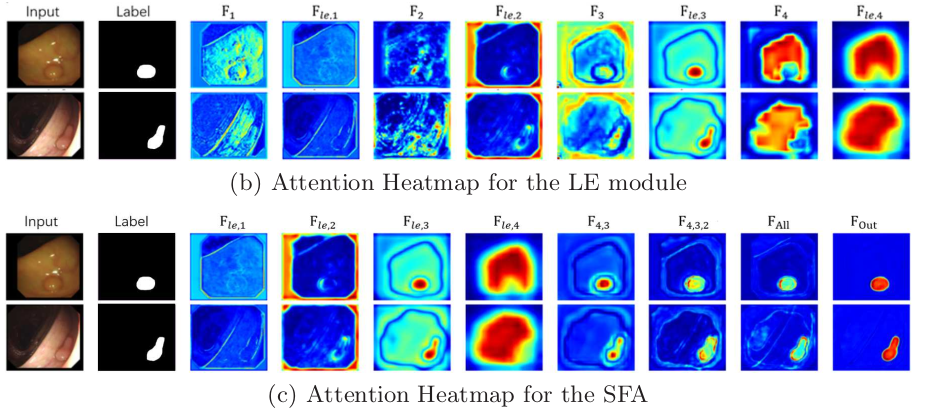
SSFormer의 overviw. 파란색은 무강조, 초록색은 Local Emphasize(LE), 빨간색은 Feature fusion을 나타냄. LE부분을 제외한 나머지 PLD 부분은 Stepwise Feature Aggregation (SFA)이라고 함
- 2018 Data Science Bowl, ISIC-2018 benchmarks에서 SOTA를 기록했었음
2. Methodology
2.1 Transformer encoder
- CNN 대신 Transformer 기반 인코더를 사용함
- PVTv2 (WANG, Wenhai, et al.)와 Segformer를 참고함
2.2 Aggregate local and global features stepwise (PLD)
- Do vision transformers see like convolutional neural networks? (RAGHU, Maithra, et al.) 연구와 **Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers (ZHENG, Sixiao, et al.) 연구에 따르면 Transformer의 shallow part에서 얻어진 local feature는 성능에 직접적으로 영향을 미침
- 그러나 이 연구진들은 기존의 Transformer기반 모델이 local, detail 정보 처리에 한계가 있다고 판단함 (윤곽이나 혈관, 텍스쳐 등)
- 그래서 LE와 SFA를 결합한 PLD 모델을 구축함
- LE 모듈이 효과적으로 노이즈를 제거하고 local feature를 강조함
- PLD를 통해 나온 feature 맵을 통해 prediction head가 target에 더 정확하게 focus 할 수 있었음



2.3 Stepwise Segmentation Transformer
- encoder 스케일에 따라 SSFormer-S (Standard), SSFormer-L (Large) 모델을 제작
3. Experiments
3.1 Experimental Setup
실험 1: (MSRF-Net 연구 참고)
- Kvasir-SEG, CVC-ClinicDB에 각각 학습+테스트 진행
- 일반화 성능을 위해 <Kvasir-SEG에 학습, CVC-ClinicDB에 테스트>와 <CVC-ClinicDB에 학습, Kvasir-SEG에 테스트>를 진행
실험 2: (PraNet 연구 참고)
- Kvasir와 CVC-ClinicDB에서 랜덤하게 1450개 이미지 추출 및 학습 + CVC-ColonDB, ETIS 데이터에 테스트함
- 정확도와 일반화 동시 평가하기 위함
실험 3: ISIC-2018과 2018 DATA Science Bowl 데이터로도 평가해봄
모델 연산 환경 및 하이퍼 파라미터
- pytorch로 구현, A100 GPU 사용, AdamW 사용, lr = 0.0001, decay rate 0.1, decay period 40
- DICE loss, BCE loss
- resize image 352 x 352
- random flipping, scaling, rotation, dilation, erosion augmentation
3.2 Results



3.3 Ablation Study


4. Conclusions
- 강건한 일반화와 학습 능력을 가진 SSFormer 제작
- 본 연구에서 제안한 Local Emphasis 모듈이 Transformer의 attention dispersion 문제를 해결할 수 있어 Transformer backbone을 최적화하는데 도움이 될 것임
최근 Medical Image Analysis 분야의 segmentation 논문들을 읽다 보면, Encoder에는 결국 Pyramid Transformer Encoder, 특히 Mix Transformer를 이용하고, Decoder를 어떻게 구성하냐에 따라 성능이 좌우되는 것 같습니다.
Ref
https://arxiv.org/abs/2208.02034
SSformer: A Lightweight Transformer for Semantic Segmentation
It is well believed that Transformer performs better in semantic segmentation compared to convolutional neural networks. Nevertheless, the original Vision Transformer may lack of inductive biases of local neighborhoods and possess a high time complexity. R
arxiv.org
https://github.com/Qiming-Huang/ssformer
GitHub - Qiming-Huang/ssformer
Contribute to Qiming-Huang/ssformer development by creating an account on GitHub.
github.com
