
CVPR2022에서 발표된 WSSS 논문입니다. 특별한 점은 Transformer의 Attention map을 이용해 기존의 CAM 기법과 유사하면서도 높은 성능을 내는 모델을 개발한 점입니다. 특히나 Multi-class token을 이용해 한 이미지에서 여러 class를 분할할 수 있다고 합니다.

1. Introduction
- 이전에도 언급했듯이, WSSS의 가장 중요한 단계는 더 정확한 pseudo segmentation ground-truth를 생성해내는 것입니다. 이를 해내기 위해 CAM 기반의 기법이 유행을 했고 다양한 확장 기법과 학습 기법이 연구되었지만, 완벽한 segmentation을 하기에는 한계가 있었습니다.
- 그러나 NLP 분야에서 핫하던 Transformer를 이용한 ViT(Vision Transformer)가 등장하면서 다양한 vision task에서 높은 성능을 보였습니다.
- ViT에서는 이미지를 patch로 분할 + 토큰화하고, 이 토큰들을 대표할 수 있는 하나의 class token을 더해 학습을 합니다. 최근에는 이 class token을 없애는 연구도 있었으나, 이 논문에서는 class token에 집중했습니다.
- DINO (Emerging Properties in Self-Supervised Vision Transformers)라는 연구에서 ViT의 feature에서, 특히나 class token의 attention map에서 semantic segmantation 정보를 얻을 수 있음을 확인했습니다. 덕분에 head가 image의 어느 부분에 집중하는지는 알 수 있었지만, 어떤 클래스인지는 구분할 수 없었습니다.
- 따라서 본 논문에서는 여러개의 class token을 도입해 한 이미지 내에서 서로 다른 class를 구분하고자 했고, 이를 이용한 Multi-class Token Transformer(MCTformer)를 제안했습니다. 단순히 class token을 늘린 건 아니고, class-aware 한 학습 전략을 같이 제시했습니다.
2. Multi-class Token Transformer
2.1. Overview


- input 이미지가 겹치지 않게 분할되고, patch token의 sequence로 변환됩니다. 이후 C개의 learnable class token이 patch token과 concatenate되고, 여기에 position embedding이 더해집니다.

- 이후 L개의 transformer block을 거쳐 나온 output class token에서 average pooling을 통해 최종 class score를 산출합니다. 기존의 transformer에서는 이 과정에서 MLP를 이용하는데, 더 강하고 class-aware 한 학습을 하기 위해 이렇게 바꾸었다고 합니다.
2.2. Class-Specific Transformer Attention Learning
Multi-class token structure design
- input 이미지를 N x N 패치로 분할, D개의 dimension을 가진 patch token으로 변환합니다.
- C개의 class token을 N^2개의 패치와 concatenate하고, position embedding을 더하여 transformer에 input으로 넣습니다.
- transformer layer는 Multi-Head Attention 모듈과 MLP 모듈, 그리고 각각의 앞에 붙어있는 Norm 레이어로 이루어져 있습니다.
Class-specific multi-class token attention
- token 간의 dependency를 잡아내기 위해 self-attention layer를 이용하고, 그중에서도 Scaled Dot-Product Attention을 이용합니다.

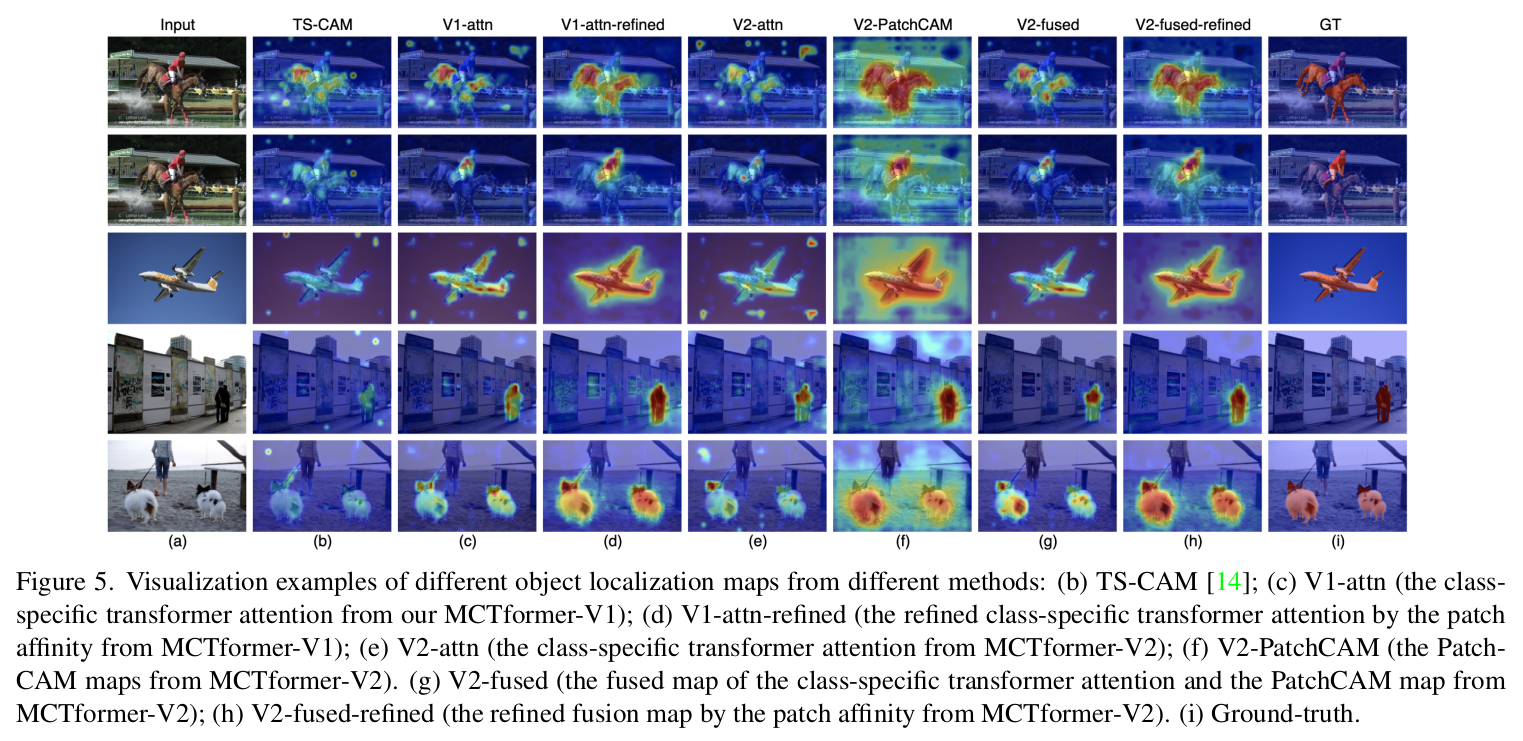
- 각 encoding layer에서 C class와 연관 있는 localization map을 뽑아낼 수 있습니다. higher layer(later layer)에서 더 분별적인 정보들을 얻을 수 있으며, 반대로 lower layer(earlier layer)에서는 더 general 한 정보를 얻을 수 있습니다.
- 마지막 K개의 layer로부터 나온 피쳐를 fuse 하여 최종 class-specific object localization map을 생성합니다.


Class-specific attention refinement

- fusion 결과 map에서 pairwise affinity map을 추출해 기존 방법과 다르게 추가적인 연산이나 학습 없이도 refinement를 할 수 있는 기법을 소개했습니다.
2.3. Complementarity to Patch-Token CAM

- 연구진은 CAM 모듈을 소개한 모델과 결합하여 MCTformer-V2를 개발하기도 했습니다.
- output class token으로 계산한 loss와 patch token을 CNN을 통해 계산한 loss를 결합하여 total loss를 계산했습니다.

- CNN layer에서 추출한 피쳐를 이용해 기존의 attention map과 행렬 곱하여 fusion을 한 뒤, patch affinity로 refine 하는 과정을 거쳤습니다.
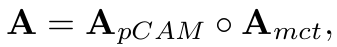

3. Experiments





5. Conclusions
- transformer-based class-specific WSSS task에서 SOTA를 달성했습니다.
- class-to-patch attention과 patch-to-patch attention을 통해 더 정확한 localization map을 생성했습니다.
- weakly supervised object detection이나 instance segmentation까지 연구하는 걸 목표로 하고 있습니다.
Ref.
CVPR 2022 Open Access Repository
Multi-Class Token Transformer for Weakly Supervised Semantic Segmentation Lian Xu, Wanli Ouyang, Mohammed Bennamoun, Farid Boussaid, Dan Xu; Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 4310-4319 Abstr
openaccess.thecvf.com
