
MICCAI 2020에서 발표된 monocular 영상을 이용해 부비동을 3D 복원하는 논문입니다. 개인적으로 비슷한 도메인에서 좋은 연구를 하고있는 Xingtong Liu라는 사람의 논문을 찾아보다가 읽게 되었습니다.
1. Introduction
- sinus anantomy (부비동 해부학)에서는 대부분 환자의 부비동 구조 이상에 따른 후두기관협착증, 폐쇄성 수면 무호흡증, 머리와 목 부위의 비강 폐쇄같은 문제가 발생합니다. 좁아진 airway 때문에 환자들이 고통을 겪습니다. 이런 질병을 치료하기위해 수십억 달러가 사용되어 환자들의 삶의 질을 크게 향상시키지만, 40% 이상의 경우가 단기간만 지속된다고 합니다.
- 일부 가설에서는 부비동의 해부학적 모양때문이라고 하지만, 객관적인 측정 방법이 없다고 합니다. 여러 기간에 거친 많은 환자의 종단 자료분석만이 부비동 모양과 수술 결과의 관계를 이해하는 데에 도움이 될 것이라고 합니다.
- 부비동 모양을 측정하는 보편적이고 정확한 방법은 CT를 이용하는 것인데, 비용이 높고 방사선을 사용하기때문에 동일한 환자의 종단 자료 (긴 시간의 자료)를 측정할 수가 없습니다.
- 내시경은 일상적으로 행해져 종단 데이터를 수집하기 좋기때문에, 내시경 영상을 통해 부비동을 분석하려면 3D surface reconstruction이 필요합니다.
- main contribution은 다음과 같습니다.
- 내시경 영상을 이용한 학습 기반의 부비동 3D surface reconstruction 기법을 소개합니다.
- 본 연구의 reconstruction 결과물이 CT 결과물과 거의 일치합니다.
- 본 연구의 효과와 정확성을 sparse, dense reconstruction 결과 및 CT 데이터를 통해 입증합니다.
2. Methods
Overall Pipeline

- 전체 파이프라인은 다음 세가지 요소로 구성됩니다.
- 1) 학습 기반의 descripter로부터 얻어진 dense point correspondences 기반의 SfM (Point cloud)
- 2) Depth estimation
- 3) surface 추출을 동반한 volumetric depth 합성
- SfM이 각 비디오 시퀀스의 대응점 (point correspondences)을 구분하고, 이것으로 sparse 3D reconstruction point와 camera trajectory를 생성합니다.
- SfM의 대응 단계에서 local을 학습기반 descripter로 대체해 Dense Descriptor Extraction을 수행합니다.
- 여기서 SfM의 결과가 정확해야한다는 점을 강조합니다. 학습 기반 모듈인 Dense Descripter Extraction과 Depth Estimation의 fine-tuning에 사용되기 때문입니다. 또한 Depth fusion과 Surface Extraction을 가이드 하는 데에도 사용됩니다.
- Depth estimation은 영상의 모든 프레임에 대한 dense depth를 측정합니다.
Training procedure
- 본 논문의 저자인 Xingtong Liu의 지난 논문들에서 Dense Descripter Extraction과 Depth Estimation 모듈을 차용했다고 합니다.
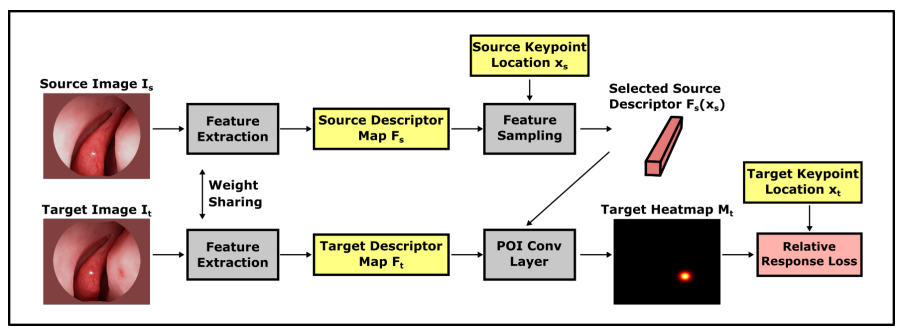

- 전체 파이프라인을 학습하기전에, 위의 두 모듈은 pre-trained 모델을 사용했습니다.
- Dense Descripter Extraction이 SfM을 생성하고, depth estimation 모델이 fine tuning 됩니다.
Structure from Motion with Dense Descriptor
- SfM이 camera 경로와 sparse reconstruction을 동시에 진행합니다. 그러나 SfM의 local feature descriptor는 smooth하고 반복되는 텍스쳐에 대해 어려움이 있습니다.
- 본 연구에서는 learning-based dense descriptor를 했으며, CNN의 global contect encoding이 가능한 점을 이용해 매칭 성능을 높였습니다.
- 높아진 매칭 성능에따라 더 많은 수의 대응점이 생기고, sparse reconstruction과 camera trajectory 예측 성능도 증가했다고 합니다.
Depth Estimation
- Dense depth estimation in monocular endoscopy with self-supervised learning methods에서 소개된 network을 차용했으나, 빛이 약한 지점에 대해서는 정확하게 예측을 하지 않기때문에 결과가 확률적이라는 것을 가정했습니다. 따라서 픽셀 차원의 Gaussian 분포를 이용해 평균과 표준편차 map을 계산했습니다. -> outlier에 대해 강건한 모델을 만들 수 있었습니다.
- self-supervised depth estimation에 일반적으로 사용되는 appearance consistency loss를 추가했으나 이것은 빛이 고정되어있는 환경에서 적용됩니다. 흥미롭게도 Dense Descriptor Extraction 모듈은 빛의 변화에 invariant 합니다.
Depth Fusion and Surface Extraction
- A volumetric method for building complex models from range images에서 소개된 truncated signed distance fuctions 기반 fusion 기법을 적용합니다.
- scale 일관성을위해 SfM 결과를 이용하며, 정확한 fusion을 위해 SfM을 통해 얻은 camera pose를 이용합니다.
- 마지막으로 Marching Cube 기법으로 정확한 triangle mesh surface를 추출합니다.
3. Experiments

- sparse reconstruction (1행), surface reconstruction 결과 (2행)
- 각 숫자는 (위에서부터) 매칭 포인트 수, 사용된 프레임 수, point-to-mesh 거리를 의미합니다.

SfM과 비교
- 33 video에 대해 그냥 SfM 기법을 사용했을 때보다 0.34 (+- 0.14) mm 의 오차가 발생한다고 합니다.

COLMAP과 비교
- 3개의 시퀀스에대해 0.24(+-0.08)mm 의 residual distance를 나타냈습니다.
- 위 숫자는 본 연구의 reconstruction과 COLMAP-B의 차이 비율입니다.
- COLMAP-B는 기존의 poisson이나 delaunay 기법이아닌 ball pivoting이라는 기법으로 reconstruct한 결과입니다. poisson과 delaunay는 안 좋은 결과를 낸다고 합니다.
- COLMAP-P는 poisson 기법으로 mesh화 한 결과입니다.
- 위 세개의 시퀀스에대해 본 연구의 기법은 127분, COLMAP은 778분이 소요되었습니다.

CT와 비교
- 7개의 비디오 시퀀스에 대해 0.69 (+-0.14) mm의 오차를 나타내었습니다.
- SfM기법은 CT 모델과 비교했을때 0.53(+-0.24) mm의 오차를 나타내었습니다. sparse recon의 특성상 에러가 더 적게 나온다고 합니다.
4. Discussion
Choice of depth estimation method
- 본 연구에서 사용한 네트워크보다 더 복잡한 네트워크 아키텍처를 사용한다면 성능을 더 끌어올릴수 있을거라고 합니다.
Limitations
- SfM의 결과가 좋지 않다면, 전체 파이프라인의 성능이 좋지 않습니다.
5. Conclusion
- 내시경 영상을 이용한 Learing-based surface reconstruction 파이프라인을 개발했습니다.
- 추후에는 uncertatinty까지 예측하는 모델을 개발할 예정이라고 합니다.
