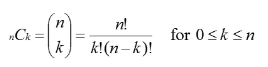파이썬으로 데이터를 다룰 때에 가장 많이 쓰는 패키지중 하나인 numpy에는 argsort()라는 유용한 메소드가 있습니다. argsort()는 아래와 같이 정렬되기 전의 인덱스를 리스트 형태로 반환합니다. import numpy as np array1 = np.array([1,0,9,3]) sort_indice = np.argsort(array1) print(sort_indice) 출력값 >>[1,0,3,2] 이를 이용해 데이터베이스에서 가져온 서로 다른 테이블의 값을 정렬할 수 있습니다. ndarray의 특성상 서로 다른 타입의 변수들은 하나의 array에 담지 못하기 때문에, 따로 불러온뒤 정렬을 해야합니다. name_array = np.array(['동혁', '유리', '진우', '태연', '동준..
2021년이 일주일이나 지나고서야 작년을 돌아봅니다. 대학생활 복수전공 과정으로 인해 한 학기를 0학점짜리 과목으로 더 해야 하긴 하지만... 제 대학생활에 마침표를 찍었습니다. 특히나 올 한 해는 개발자로서 특별한 한 해를 보냈습니다. 정말 프로젝트다운 프로젝트를 해보고, 현업에 종사하는 사람들도 많이 만나보고, 취업활동을 하며 제 역량에 대해 다시 한번 되돌아보았습니다. 어쩌면 대학교를 다닐 때가 가장 감사할 때라고 생각을 했습니다. 무엇이든 도전해볼 수 있었고 배우고 싶은 것을 배우며 다양한 경험을 할 수 있었던 것 같습니다. 자기 계발 과연 제가 학업 이외의 자기 계발을 잘했는지 되돌아봅니다. 질러놓은 책은 많으나 역시 한 챕터도 넘어가지 못한 것들이 수두룩했습니다. 그렇지만 제가 진행했던 추천 ..
지난 11월 마이다스아이티 경영솔루션 직무에 지원하여 생애 처음으로 면접이란 걸 봤습니다. 특이하게 이 회사는 AI면접을 두 차례 보더라구요. AI면접에 대해선 준비를 하나도 안했었는데, 실제로 진행했을때는 정말 사람과 면접을 하는 것 처럼 긴장됐습니다. 그리고 기술면접을 보았지만 긴장했는지 제대로 답변 못한 부분이 많았고, 아쉽게도 떨어졌습니다. 제 마음도 다잡고 다시한번 복습해볼겸 이렇게 남겨봅니다. 혹시나 문제가 된다면 삭제하겠습니다. AI면접 1차 AI:자기소개 AI 안내에 따라 카메라를 보며 1분? 간 자기소개를 합니다. 저는 간단히 저를 나타낼수 있는 단어 몇글자로 표현을 했고, 이어서 남들보다 특별한 점을 말했습니다. 저는 좋아하는 분야가 있으면 분석이나 개발을 해보는 추진력을 가지고 있는 ..
데이터 분석 또는 엔지니어링 분야로 취업 준비를 하고 있습니다. 교육과정 문제로 학교를 내년 1학기까지 다녀야해서 졸업요건이 안 맞는 기업이 많아 지원을 많이 못했지만, 그나마 졸업요건 제한이 없는 기업이나 인턴 위주로 지원하고 있습니다. 잘 됐으면 좋겠습니다... 🤣 - 2020.08.25 카카오 개발자 블라인드 공채에 지원했습니다. 1지망: 카카오 - 데이터 분야 2지망: 카카오페이 (코테 불합) - 2020.09.07 LINE PLUS에 지원했습니다. server부문 data science & platform 졸업 시기의 불충족으로 불합 - (날짜 까먹음) sk C&C Data analysis/Data engineering 신입 서류 광탈... - 2020.10.31 카카오 추천팀 겨울인턴 지원 개..
일반적으로 Queue는 FIFO 형식의 자료구조지만, Priority Queue는 들어간 순서에 상관없이 데이터의 크기에 따라 정렬됩니다. 따라서 heap구조와 비슷하다고 볼 수있습니다. 이를 파이썬으로 구현하려면 queue 혹은 heapq를 이용하면 되는데요. import queue q = queue.PriorityQueue() q.put(5) q.put(2) q.put(3) q.put(1) while not q.empty(): print(q.get()) #출력 1 2 3 5 위와같이 순서를 달리해도 정렬되서 출력이 됩니다. 그러나 파이썬 프로그래밍을 할 때에는 단순 숫자가 아닌 객체를 넣기도 하는데요. 아래와 같이 코드를 입력하고 실행하면 에러가 발생합니다. class Data: def __init_..
여태까지 python 가상환경 구성을 위해 Anaconda를 사용해왔습니다. 데이터분석에 필요한 패키지는 모두 설치되어있으니깐요 그러나 최근들어 쓸모없는 패키지가 너무 많이 설치되는 것 아닌가하는 마음에 지인의 추천을 받아 python virtualenv를 사용하는게 더 가볍고 관리하기도 편해보였습니다. 따라서 제가 사용하는 linux에서 anaconda를 삭제하려고 합니다. 그런데 어떻게 삭제할까요? 방법 1. anaconda 디렉토리를 삭제 simple uninstall 입니다. 그냥 linux에 설치된 anaconda 디렉토리를 삭제합니다. rm -rf ~/anaconda3 방법 2. anaconda-clean 설치 후 삭제 사실 이 방법을 실행하신 다음에 방법1을 해야 full uninstall이..
프로젝트를 진행하다보니 학교에서 대여한 클라우드 서버에서 개발할 필요성을 느꼈고, 윈도우에서 리눅스를 쓸 방법을 생각해보다가 윈도우의 좋은 기능을 찾아서 기록해봅니다. WSL은 마이크로소프트에서 개발한 Window Subsystem for Linux 입니다. 말 그대로 윈도우에서 리눅스를 사용할 수 있도록 개발된 것입니다. 그동안 개발자라면 맥북이 국룰이라고만 생각했는데, WSL를 통해서라면 제가 굳이 맥북을 살 이유는 좀 사라진 것 같네요... 그래도 가지고 싶긴 합니다. 사실 마소에서 몇 년전에 개발되었지만, 저는 올해가 되어 WSL2가 나오고서야 알게 되었습니다. 따라서 WSL2를 사용하려면 윈도우도 1903버전(x64기준) 이후로 업데이트 해주셔야 합니다. 업데이트는 여기서 할 수 있습니다. Wi..
개발하다보면 git을 사용하는 경우가 많은데 종종 명령어 순서를 까먹습니다... 자주쓰면 외워지긴 하겠지만 본 게시물 작성을 통해 머리에 때려 박아야겠습니다. Github repository를 해당 디렉토리에 복사합니다(불러옵니다.) git clone 해당 폴더에 .git을 생성하고 초기화합니다. (깃의 관리를 받게됩니다.) git init (로컬 폴더와 연결할) 원격 repository를 새로 생성합니다. git remote add # git remote add origin https://github.com/~~ 변경점이 있는 파일을 stage에 올립니다. ( .는 해당 폴더의 모든 파일) git add . 커밋을 통해 서버에 올릴 준비를 완료합니다. git commit -m "커밋 메세지" 커밋한 내..
본 게시물은 경희대학교 한치근 교수님의 '알고리즘분석' 강의를 듣고 노트한 내용입니다. 원래는 multistage decision processes라고 불렸으나 정부기관의 관료에게 그럴듯하게 보이기 위해 dynamic으로 명명함 분할정복식은 하향식 해결법 (top-down approach), 서로 상관관계가 없는 문제를 해결하는 데에 적합 그러나, 피보나치 알고리즘은 같은 항이 여러번 호출됨 -> 비효율적 동적계획법 상향식 해결법 (bottom-up approach) 문제를 나눈 후에 작은 문제들을 먼저 푼다. 이항계수 구하기 계산량이 많은 n!과 k!를 계산하지않고 이를 부분으로 나눈다. 1) 분할정복식 *재귀호출을 할 때 같은 계산을 반복해서 수행하게됨. -> 비효율성 증대 2) 동적계획식 2차원 배..
2020년 상반기 중 '빅데이터를 통한 데이트코스 추천 시스템 개발' 프로젝트를 진행한 적이 있습니다. 데이트 코스를 정하기 힘들어하는 사람들을 위해 맛집, 데이트 명소, 볼만한 영화를 한꺼번에 추천해주는 시스템이며, 단순히 사람들이 좋아하는 장소가 아닌 본인의 취향을 고려한 장소를 추천하는 시스템입니다. 저를 포함해 총 3명의 팀원이 진행을 했으며, 어느 한 사람이 역할을 맡기보단 위에서 언급한 맛집, 데이트명소, 영화 3가지 분야로 나누어 python을 통한 데이터 수집 및 전처리부터 모델링까지 모든 과정을 수행했습니다. 저는 그중 '맛집' 분야의 데이터 수집, 전처리, 모델링 과정을 수행하고, Neural Collaborative Filtering 모델을 리서치함과 동시에 적용할 수 있는 코드를 작..